Yes, we reinstalled the entire genie-toolkit and repeated the entire installation process (using git clone, npm install and npm link).
Well, you made changes to the genie-toolkit source. Did you run npm install before or after making those changes?
I think we did it directly after the git clone stage. We’ll try running npx make or reinstalling it again but running npm install after we changed the files tomorow.
Update:
After running the npx make command, it seems that the training data generation can run without error. We’ll share more updates when the command has stopped running.
Update2:
The output is here:

How do we check if it has generated the training data correctly?
and how do we do the next step for training using this data? The documentation said that the command is
make train but there is no train command in the Makefile. The closest thing is train-user.
Update 3:
We tried to install genienlp and run the make train-user command, but got the following error:
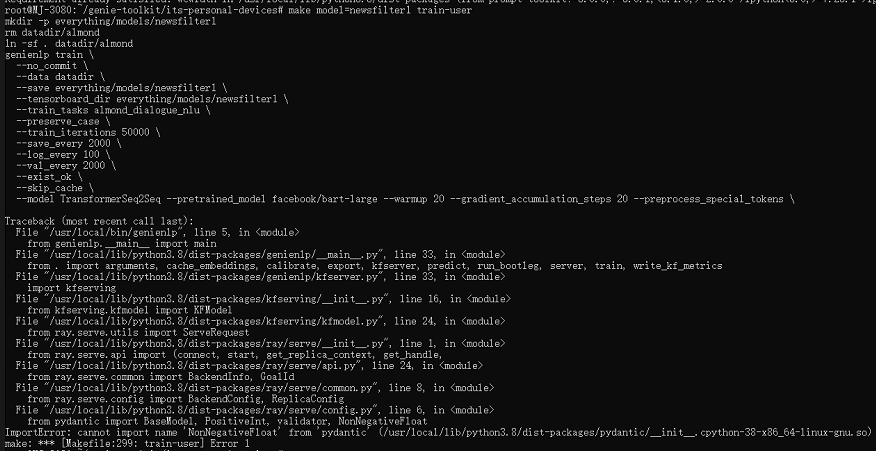
That’s a versioning issue with the latest release of one of genienlp’s dependencies. Installing genienp 0.7.0a2 should fix the issue.
It doesn’t seem to solve the issue, we are still getting the same error as before (using the make train-user command):
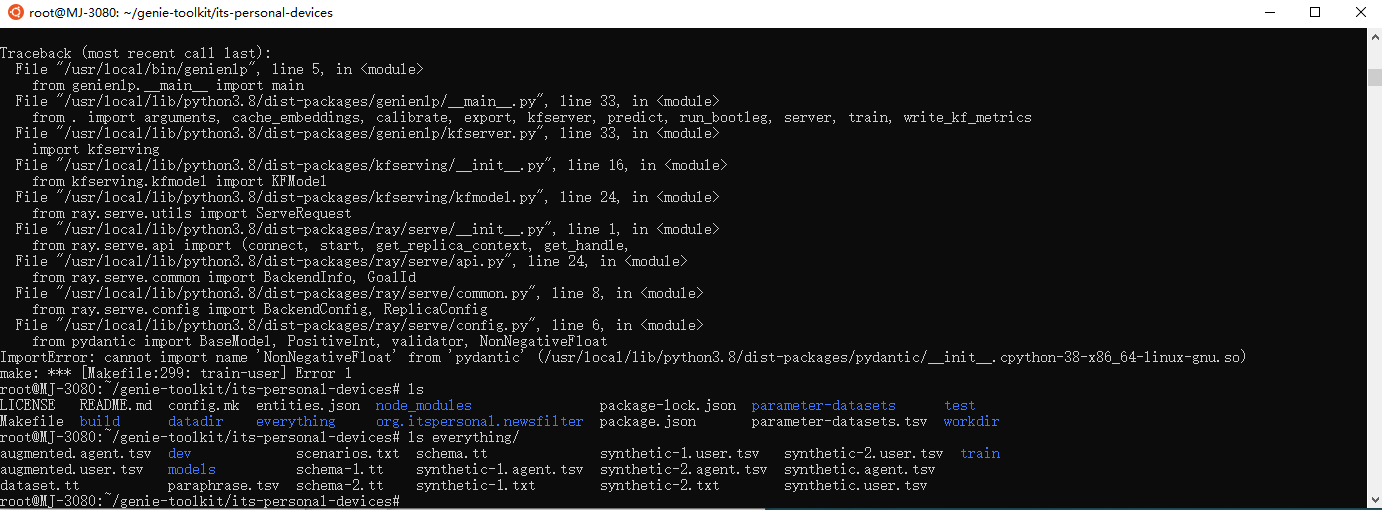
Also at the bottom of the screenshot you can see the contents of our everything folder. Does this mean that we did the generate training data part correctly? If so I will make the pull request for the genie-toolkit github.
Yeah the dataset looks correct.
If the versioning issue is not correct, pip uninstall pydantic then reinstall genienlp pip install genienlp==0.7.0a2. Also make sure you’re using a recent pip, or pass --use-feature=2020-resolver
We installed pip using apt install python3-pip, should that be a recent enough version? Also, our current machine has 32 GB RAM, would that suffice for the default training command or are there some tunable settings like for generating the training data?
If we managed to fix the issue, what should we do next? Will it instantly work in the local Almond (e.g. we can use natural language in genie-assistant and scenarios.txt) or do we need to do another step?
After that, how do we use it in the Web Almond through the almond.stanford.edu website for testing and through the API for the actual website we are making (assuming both are possible)?
Whether the apt version is recent enough depends on the distro version. Typically, pip bugs you about upgrading when it starts. It will work if it has the --use-feature=2020-resolver flag (but if it’s very recent, it will then warn you that the option is deprecated)
Yeah the memory should be enough for normal training without Bootleg, especially if your dataset is not huge.
Once you have trained the model, you can point all Genie command line tools to it using a file:/// URL, or you can deploy the model for serving through an API using the genie server command.
At the moment though, you cannot point almond.stanford.edu to a custom NLP server. But I seem to recall you have a local almond-cloud install instead? If you have that, changing the NLP server URL in the config to the URL exposed by genie server should work.
We fixed it by uninstalling the pydantic package and fully reinstalling the genienlp. However, it has a new error after running more steps as follows:
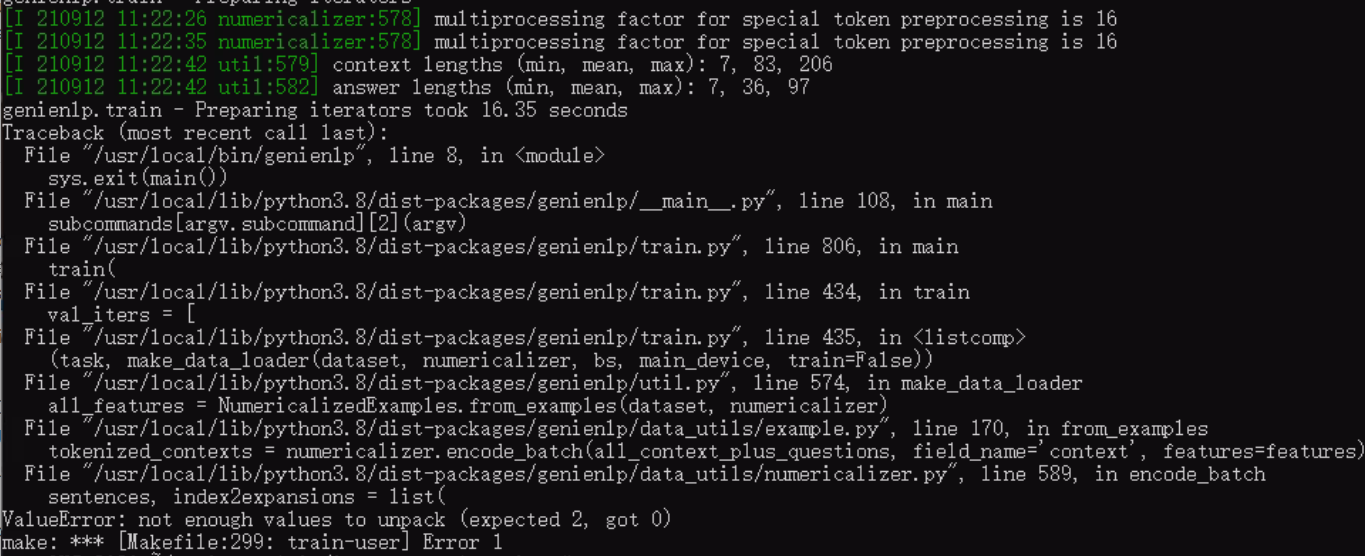
In genie-assistant --help, there is two different NLP arguments, `–nlu-server’ and ‘–nlg-server’, which one do we use?
The issue might be that you don’t have any validation data. Writing some data in everything/dev/annotated.txt should help. You can look at the annotated.txt files in thingpedia-common-devices for examples of the syntax, and also the guides in the doc folder of that repo.
Use the --nlu-server option (NLU = natural language understanding, NLG = natural language generation).
From what I can see from the existing devices, there seems to be two different folders with the annotated.txt file, dev and train. From your explanation we only need to do the dev one, but in the existing devices, both folders are located under eval in the same folder as scenarios.txt instead of in everthing. Which folder should they be located in? and can you explain what the differences are between the dev and train folder?
For the contents of the annotated.txt file itself, I’m unable to find a documentation for it, with the closest I could find is this one which is about building a dialogue model. However, from the annotated.txt file that I could find in the existing devices, the format seems to be the following:
# online/62110261
U: i want to use bing to search something
UT: $dialogue @org.thingpedia.dialogue.transaction.execute;
UT: @com.bing.web_search();
U seems to be the example natural language used.
The first UT seems to be always $dialogue @org.thingpedia.dialogue.transaction.execute;
The second UT seems to be the Thingtalk command.
What I’m unsure of is the comment at the top. Some lines have it as online/$randomnumbers while others have it as log/$randomnumbers. Can you explain a bit more about this part?
Finally, would the text for our code look something like this:
# online/1
U: I want to search for sports articles
UT: $dialogue @org.thingpedia.dialogue.transaction.execute;
UT: org.itspersonal.newsfilter.news_articles(topic="sports")
The directory layout of the thingpedia-common-devices repo is slightly different than that of a project initialized with genie init-project because t-c-d has a concept of “releases”, which are groups of devices that can be enabled at the same time.
In a simple project, there is only one release called “everything”, which is at the top-level of the repository. In t-c-d, there is only release called “everything”, and three releases called “main”, “universe”, “staging” that are automatically computed by subsetting “everything”)
annotated.txt files can also be put in eval/dev inside each device directory instead of in a release directory. In that case, you’ll want to put only data specific to that device in the annotated.txt
In your case, you only really have one device, so it does not make a difference.
The format of the file has dialogues, separated by ====.
Each dialogue starts with # followed by the ID of the dialogue. The ID is a free-form string. The only requirement is that it is unique. For our own dataset we follow some conventions related to where the data came from; e.g. “log/” means that the data came from usage logs collected from real users.
Other lines that start with # are comments.
Following the ID, are the turns in sequence:
- U: the user utterance
- UT: the user target: this is a dialogue state (with the $dialogue prefix, the policy name
@org.thingpedia.transactionand the dialogue actexecute) containing the commands that the user wants to execute - C: the context: the result of accumulating all previous user states in the same dialogue and executing them
- A: the agent utterance
- AT: the agent target: a formal interpretation of the agent utterance; it is combined with the context to form the input to the neural model to interpret the next user utterance
Note that the user speaks first and last, so each dialogue starts with U: and ends with UT:. The last reply from the agent is not important and is discarded.
Often, there is only one turn in a dialogue, so there is only one pair of U and UT.
So yeah, I think the example you show is a correct way to annotate the data.
We managed to write an annotated.txt file and put it in everything/dev, everything/train, eval/dev, and eval/train. However, we are still getting the same error as before:
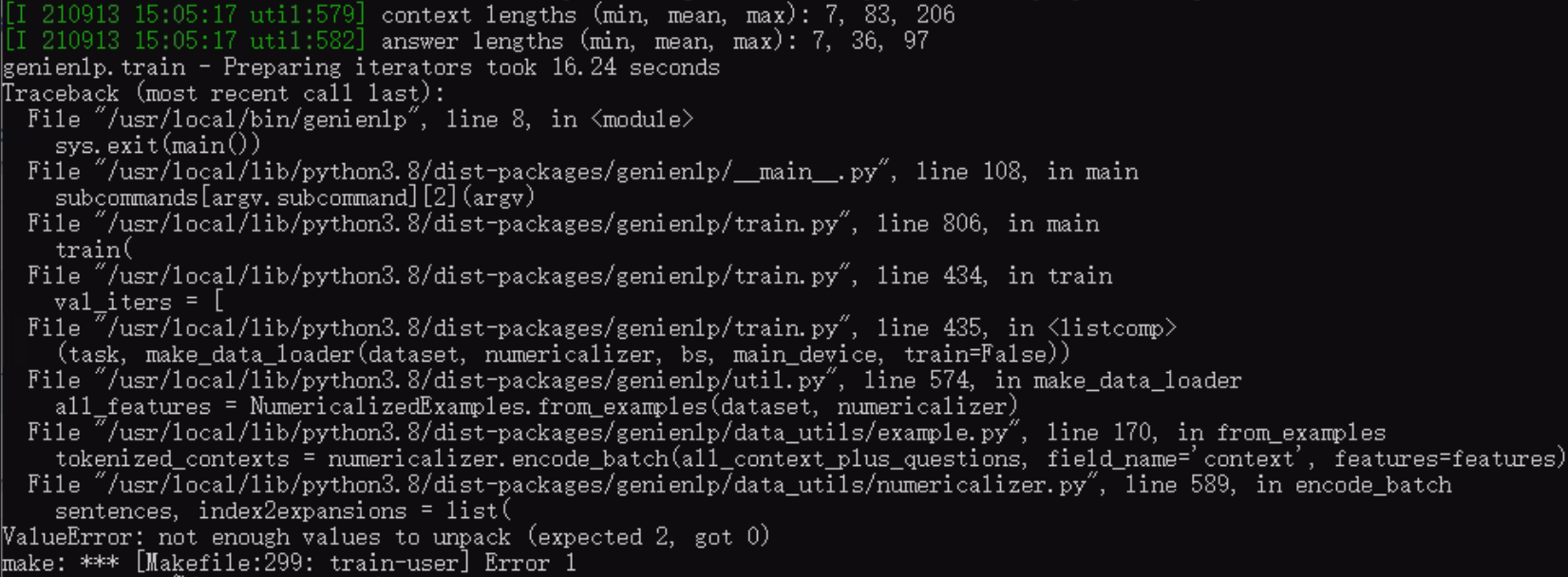
The entire
annotated.txt file can be found here but the following is a snippet to show that it should be working fine:
====
# online/1
U: I want to search for sports articles
UT: $dialogue @org.thingpedia.dialogue.transaction.execute;
UT: @org.itspersonal.newsfilter.news_articles(topic=enum sports)
# online/5
U: I want to search for tech articles
UT: $dialogue @org.thingpedia.dialogue.transaction.execute;
UT: @org.itspersonal.newsfilter.news_articles(topic=enum tech)
# online/9
U: I want to start training for sports topic
UT: $dialogue @org.thingpedia.dialogue.transaction.execute;
UT: @org.itspersonal.newsfilter.training_news_articles(topic=enum sports)
C: $dialogue @org.thingpedia.dialogue.transaction.execute;
C: @org.itspersonal.newsfilter.training_news_articles(topic=enum sports)
C: #[results=[
C: { id="Australia is shaping up to be the villain of COP26 climate talks\\sports"^^org.itspersonal.newsfilter:training_news_article, title="Australia is shaping up to be the villain of COP26 climate talks", description="If Australia's allies were worried that the country might cause them problems at upcoming climate talks in Glasgow, the events of the past week should leave little doubt in their minds. It will.", link="https://www.cnn.com/2021/09/12/australia/australia-climate-cop26-cmd-intl/index.html"^^tt:url, topic=enum sports }
C: ]];
A: Here is a random article. Would you like to label it?
AT: @org.thingpedia.dialogue.transaction.sys_recommend_one;
AT: @org.itspersonal.newsfilter.mark_training_news_article(id="Australia is shaping up to be the villain of COP26 climate talks\\sports"^^org.itspersonal.newsfilter:training_news_article) #[confirm=enum proposed];
U: Yes
UT: $yes;
C: $dialogue @org.thingpedia.dialogue.transaction.execute;
C: @org.itspersonal.newsfilter.training_news_articles(topic=enum sports)
C: #[results=[
C: { id="Australia is shaping up to be the villain of COP26 climate talks\\sports"^^org.itspersonal.newsfilter:training_news_article, title="Australia is shaping up to be the villain of COP26 climate talks", description="If Australia's allies were worried that the country might cause them problems at upcoming climate talks in Glasgow, the events of the past week should leave little doubt in their minds. It will.", link="https://www.cnn.com/2021/09/12/australia/australia-climate-cop26-cmd-intl/index.html"^^tt:url, topic=enum sports }
C: ]];
C: @org.itspersonal.newsfilter.mark_training_news_article(id="Australia is shaping up to be the villain of COP26 climate talks\\sports"^^org.itspersonal.newsfilter:training_news_article);
A: Is this article relevant to the topic?
AT: @org.itspersonal.newsfilter.mark_training_news_article(id="England vaccine passport plans ditched, Sajid Javid says\\tech"^^org.itspersonal.newsfilter:training_news_article);
U: No
UT: $no
How many tests do you think we should have? Also do we need to make one for mark_training_news_article even though it wont ever be called directly (maybe its required by the training)?
Did you rerun make datadir after adding the annotated file? It’s required to process those input files to a format that genienlp can consume.
make datadir (or make datadir/fewshot which is a bit faster) will also catch any syntax error in the validation data. For example, in the snippet you show you need to separate different dialogues with ====
Also, do you have the earlier lines in the error log, just to be sure?
As for your question, generally you’ll want a few hundred turns of validation data to get an accuracy measurement that is meaningful.
You only need sequences of commands and thingtalk that are meaningful to users. If you think a certain command will never be called directly, then you don’t need at the first turn in the dialogue.
(But keep in minds - users rarely do what conversation designers want them to do!)
No we did not. So we need to run make subdatasets=2 target_pruning_size=150 datadir every time we make some changes to the annotated.txt file?
And yes we did include the ==== part, I just copied it wrong. I’ll post the picture of the entire terminal output from running make model=newsfilter1 train-user if its still having issues after the rerun.
Edit:
For some reason when running the make datadir command, we are now getting this error:
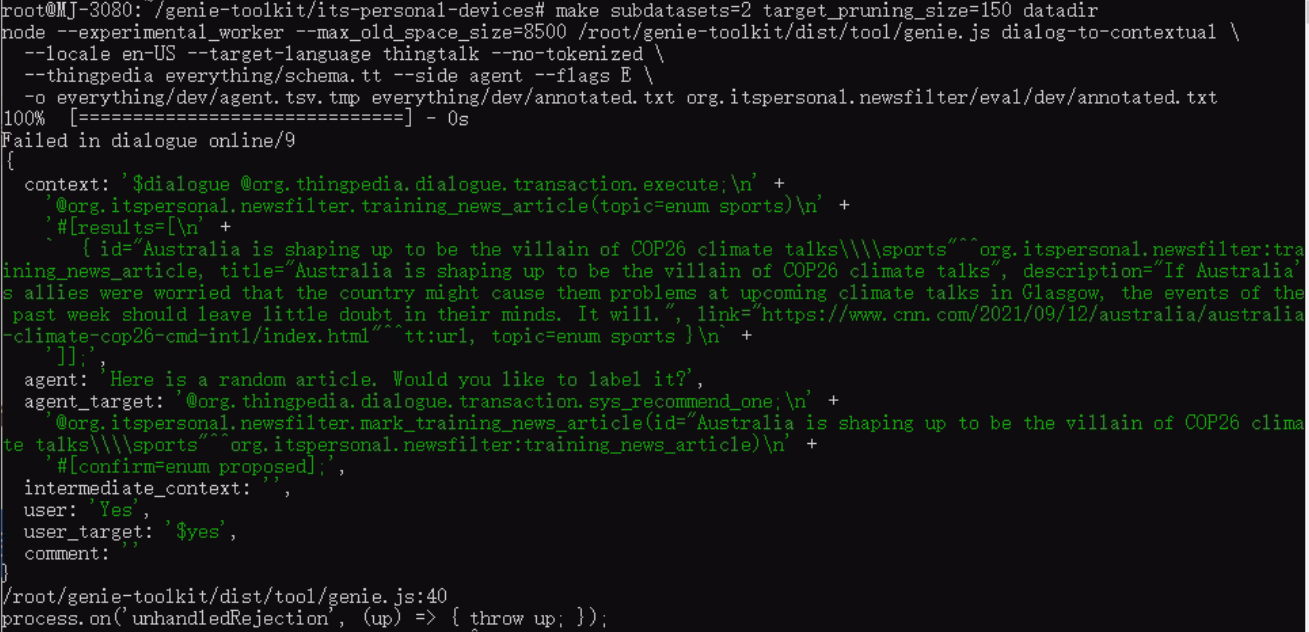
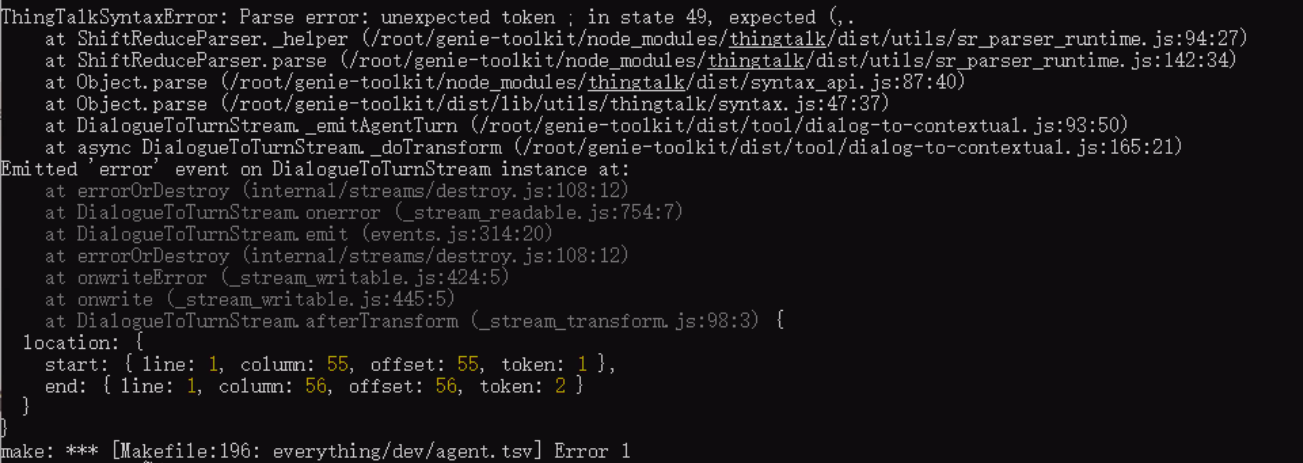
Our dialogue entry is the following:
====
# online/9
U: I want to start training for sports topic
UT: $dialogue @org.thingpedia.dialogue.transaction.execute;
UT: @org.itspersonal.newsfilter.training_news_article(topic=enum sports)
C: $dialogue @org.thingpedia.dialogue.transaction.execute;
C: @org.itspersonal.newsfilter.training_news_article(topic=enum sports)
C: #[results=[
C: { id="Australia is shaping up to be the villain of COP26 climate talks\\sports"^^org.itspersonal.newsfilter:training_news_article, title="Australia is shaping up to be the villain of COP26 climate talks", description="If Australia's allies were worried that the country might cause them problems at upcoming climate talks in Glasgow, the events of the past week should leave little doubt in their minds. It will.", link="https://www.cnn.com/2021/09/12/australia/australia-climate-cop26-cmd-intl/index.html"^^tt:url, topic=enum sports }
C: ]];
A: Here is a random article. Would you like to label it?
AT: @org.thingpedia.dialogue.transaction.sys_recommend_one;
AT: @org.itspersonal.newsfilter.mark_training_news_article(id="Australia is shaping up to be the villain of COP26 climate talks\\sports"^^org.itspersonal.newsfilter:training_news_article)
AT: #[confirm=enum proposed];
U: Yes
UT: $yes;
C: $dialogue @org.thingpedia.dialogue.transaction.execute;
C: @org.itspersonal.newsfilter.training_news_article(topic=enum sports)
C: #[results=[
C: { id="Australia is shaping up to be the villain of COP26 climate talks\\sports"^^org.itspersonal.newsfilter:training_news_article, title="Australia is shaping up to be the villain of COP26 climate talks", description="If Australia's allies were worried that the country might cause them problems at upcoming climate talks in Glasgow, the events of the past week should leave little doubt in their minds. It will.", link="https://www.cnn.com/2021/09/12/australia/australia-climate-cop26-cmd-intl/index.html"^^tt:url, topic=enum sports }
C: ]];
C: @org.itspersonal.newsfilter.mark_training_news_article(id="Australia is shaping up to be the villain of COP26 climate talks\\sports"^^org.itspersonal.newsfilter:training_news_article);
A: Is this article relevant to the topic?
AT: @org.itspersonal.newsfilter.mark_training_news_article(id="Australia is shaping up to be the villain of COP26 climate talks\\sports"^^org.itspersonal.newsfilter:training_news_article);
U: No
UT: $no;
Is there some typo somewhere that we aren’t seeing? I copied the output from running the scenario test so the syntax should be correct.
I’m sorry you cut off the log right before it showed you the underlying error, so I’m not sure. But it’s likely an error in your data.
One thing that I noticed is that you used short forms $yes; and $no;. Those are handled by the runtime but are not valid in the dataset because they are not dialogue states. You should replace them with the correct dialogue state. Eg. when you say “Yes” the first time, the annotation should be:
$dialogue @org.thingpedia.dialogue.transaction.execute;
@org.itspersonal.newsfilter.mark_training_news_article(id="Australia is shaping up to be the villain of COP26 climate talks\\sports"^^org.itspersonal.newsfilter:training_news_article);
because that’s the command the user would like to execute at that point, given the context of the dialogue.
(If you haven’t already, I suggest reading this paper which explains how dialogue states work. We have a much better revision of that paper but I cannot post it publicly due to anonymity requirements. I’ll see if I can share it with you).
Anyway yeah any time you make changes to data you should run make datadir. It will be fast if it doesn’t need to synthesize again.
There is no other part of the log from the screenshot, below the make: message the output ends. I based the initial version on the output of the scenario tests, maybe the correct dialogue state would be the closest command that’s after/before $yes / $No.
Edit:
After trying the changes, I think the problem is somehow the first context part, not the user target after that. For some reason it doesn’t want to accept C: $dialogue @org.thingpedia.dialogue.transaction.execute; and will mark the ; as an error. We tried removing that one but it then raises an error because the next line C: @org.itspersonal.newsfilter.training_news_article(topic=enum sports), is also a command. We then tried removing the $dialogue command entirely, but it then searches for a ; and wouldn’t let the training_news_article command not have it. So the problem seems to not be something specific about our device but rather an error in reading the $dialogue command which should be the same for all devices.
We fixed the dialogue entry as follows (added ; where needed and fixed the $yes and $no part):
====
# online/9
U: I want to start training for sports topic
UT: $dialogue @org.thingpedia.dialogue.transaction.execute;
UT: @org.itspersonal.newsfilter.training_news_article(topic=enum sports);
C: $dialogue @org.thingpedia.dialogue.transaction.execute;
C: @org.itspersonal.newsfilter.training_news_article(topic=enum sports)
C: #[results=[
C: { id="Australia is shaping up to be the villain of COP26 climate talks\\sports"^^org.itspersonal.newsfilter:training_news_article, title="Australia is shaping up to be the villain of COP26 climate talks", description="If Australia's allies were worried that the country might cause them problems at upcoming climate talks in Glasgow, the events of the past week should leave little doubt in their minds. It will.", link="https://www.cnn.com/2021/09/12/australia/australia-climate-cop26-cmd-intl/index.html"^^tt:url, topic=enum sports }
C: ]];
A: Here is a random article. Would you like to label it?
AT: @org.thingpedia.dialogue.transaction.sys_recommend_one;
AT: @org.itspersonal.newsfilter.mark_training_news_article(id="Australia is shaping up to be the villain of COP26 climate talks\\sports"^^org.itspersonal.newsfilter:training_news_article)
AT: #[confirm=enum proposed];
U: Yes
UT: $dialogue @org.thingpedia.dialogue.transaction.execute;
UT: @org.itspersonal.newsfilter.mark_training_news_article(id="Australia is shaping up to be the villain of COP26 climate talks\\sports"^^org.itspersonal.newsfilter:training_news_article);
C: $dialogue @org.thingpedia.dialogue.transaction.execute;
C: @org.itspersonal.newsfilter.training_news_article(topic=enum sports)
C: #[results=[
C: { id="Australia is shaping up to be the villain of COP26 climate talks\\sports"^^org.itspersonal.newsfilter:training_news_article, title="Australia is shaping up to be the villain of COP26 climate talks", description="If Australia's allies were worried that the country might cause them problems at upcoming climate talks in Glasgow, the events of the past week should leave little doubt in their minds. It will.", link="https://www.cnn.com/2021/09/12/australia/australia-climate-cop26-cmd-intl/index.html"^^tt:url, topic=enum sports }
C: ]];
C: @org.itspersonal.newsfilter.mark_training_news_article(id="Australia is shaping up to be the villain of COP26 climate talks\\sports"^^org.itspersonal.newsfilter:training_news_article);
A: Is this article relevant to the topic?
AT: $dialogue @org.thingpedia.dialogue.transaction.execute;
AT: @org.itspersonal.newsfilter.mark_training_news_article(id="Australia is shaping up to be the villain of COP26 climate talks\\sports"^^org.itspersonal.newsfilter:training_news_article);
U: No
UT: $dialogue @org.thingpedia.dialogue.transaction.execute;
UT: @org.itspersonal.newsfilter.mark_training_news_article(id="Australia is shaping up to be the villain of COP26 climate talks\\sports"^^org.itspersonal.newsfilter:training_news_article, relevant=false);
Here is the complete terminal output that shows there is no log after make: error:
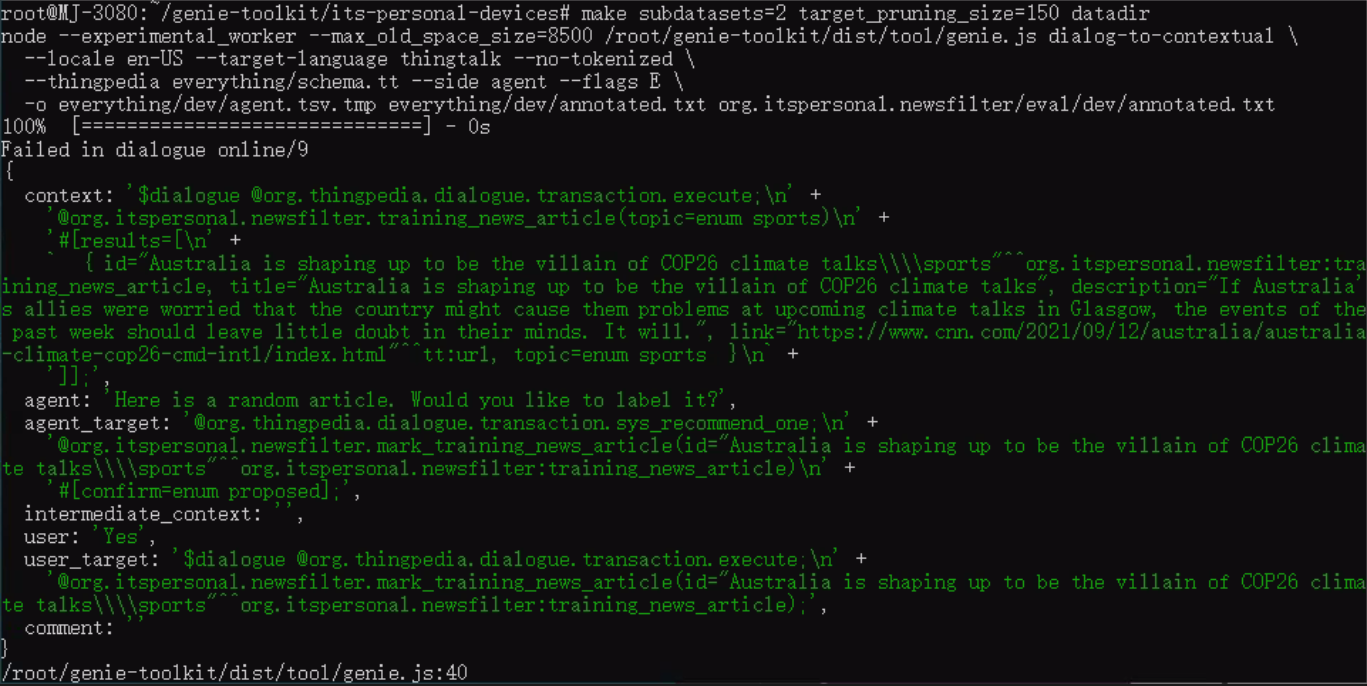
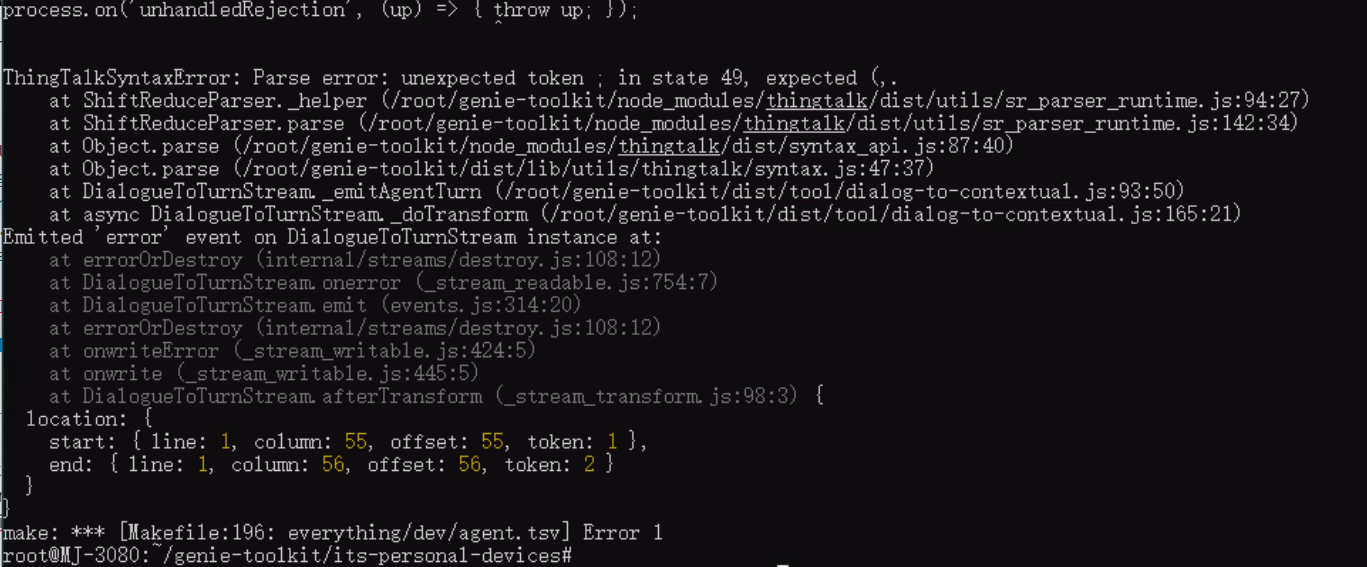
From the location with the start and end points, it seems to refer to the first line which is the
C: $dialogue command and the column/offset refers to the ; at that command. We checked using the changes we mentioned to see if it correctly refers to the commands we mentioned and it does change the line/column/offset as we expected.
The error is in the first AT, which is missing $dialogue at the beginning.
Thanks for finding the missing part, it worked after we added $dialogue to all the AT: parts that need them.
However, when running the training itself, we noticed that it ran for quite a while. After 1.5 hours, we only managed to get to iteration 600/50.000. Is the 50.000 iteration actually a set requirement for the train iterations or can we reduce it to a smaller size? Using our current computer, we estimate that it would take 125 hours of continuous running the training, which is something we would like to avoid if at all possible.
The train-user command seems to have the following setup:
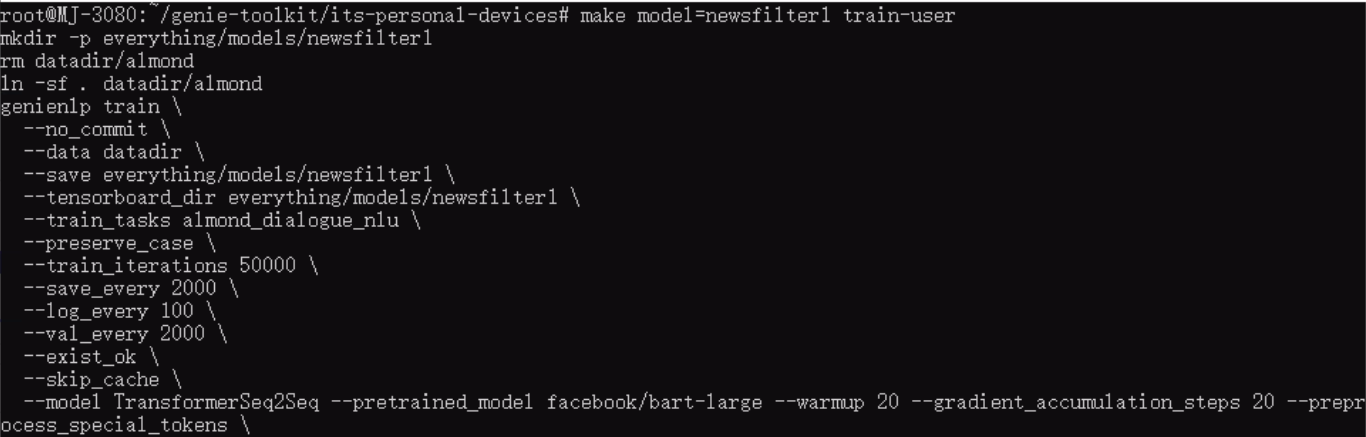
We stopped it after around 1.5 hours as follows (100 iterations every 15 mins):
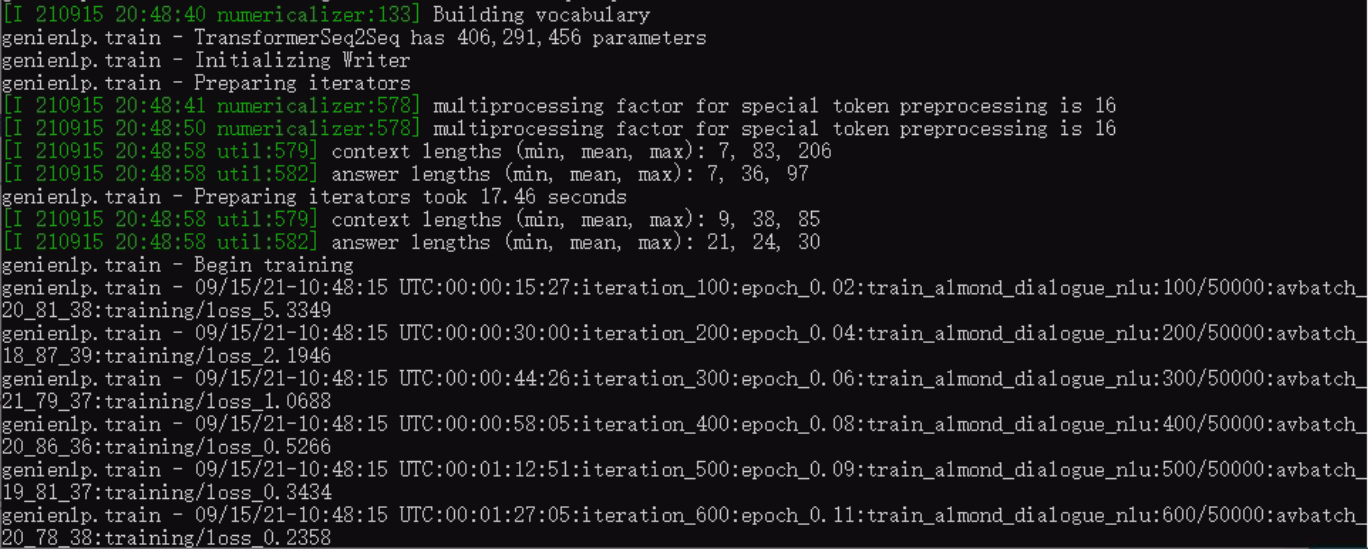
The full terminal output is as follows:

Do you have a GPU in that machine, and is CUDA correctly configured for PyTorch?
Typically you can get very close to the full accuracy with 15k to 20k iteration, and the rest is picking up small stuff. But it seems to me the problem is bigger if it’s not completing in a few hours.